Line Balancing
11 May 2021Some Background
Like my other posts, the inspiration for this came from a class I recently took on optimization. While the course mostly covered linear and mixed integer programming, there were hosts of examples covering many use cases. Oddly enough, I have been thinking about writing a script to automate line balancing for a while now but lacked the inspiration to just sit down and do it. I have looked for solutions using solvers in the past, but most end up being schedulers that lack a focus on maximizing utilization or just require way too much manual hard coding. The book we were using had a good example of a typical line balance problem, so I thought I would port it over to Python and make some minor tweaks to generalize the application. I think I have made a program that is about 95% automated, save for entering cycle times and the sequence of process steps. Put in your own process and give it a test drive.
tl;dr Run the script in the cloud here: Colab Notebook
What is a Line & Why Should it be Balanced?
Line Balancing is one of the simplest, yet most impactful tools that an Industrial Engineer has in their toolkit. When we talk about a line, we are talking about an assembly line, or a series of workstations that work in sequence. In a manufacturing environment, line balancing is the science of distributing process steps across a set of workstations to minimize the number of workstations, \(W\), and maximize utilization, \(u\), while still meeting the takt time. This minimizes WIP and through balancing of cycle times at each station, maximizes utilization, reducing waiting time. Because line balancing, in its simplest form, takes the process as-is, and simply rearranges the tasks, it can provide an incredible return on investment for unbalanced systems.
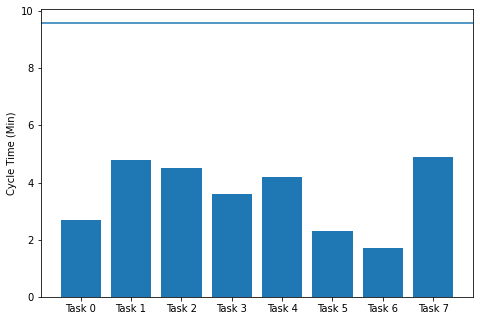
Line balancing is all about maximizing output to the takt time, but why is this important? When we think about a production line, it is like an accordion. We know from Little’s Law that at steady state, a system outputs at the bottleneck rate, \(r_b\). In its fastest, but likely least balanced form, each distinct process step has its own workstation. This leads to the most workstations, but the lowest \(r_b\). In The process below, the system will produce a part every 4.9 minutes at the last station. However, you notice that there is quite some space between the top of each bar and the takt time of 9.6. This is where utilization is important. To minimize costs, we want to create product at the speed we consume it, or the taxt time. No more, no less. If the takt time is below \(r_b\), we can look at combining steps to reduce the number of workstations and increase utilization. As takt decreases towards \(r_b\), we can continue to add process steps, unfolding the line with more stations, to lower the \(r_b\) of the system and still meet the takt.
While performing line balancing seems simple, this quickly gets complicated as process dependencies emerge and meaningful reductions in cycle times may require significant re-engineering of the product or process. It is not always as simple as adding more labor or stations to the system. After all, to minimize WIP, we want to minimize the number of stations \(W\), and to reduce costs, we want to maximize line utilization. With this simple objective and constraints, an optimization problem is born.
But First, A Disclaimer
We can manually balance a line with good old-fashioned whiteboards and post-it notes. Frankly, it is probably quicker in most cases. However, this blog isn’t about applying pragmatic solutions to complex problems—we like to indulge ourselves in automation and high-tech tools for even the simplest use cases. For today’s exercise in self-indulgence, we are exploring the application of Mixed Integer Programming (MIP) to automate our line balancing problems.
MIP & The Line Balancing Problem
Now, there are a couple options for solving MIP problems, and optimization in general. There’s PuLP, CPLEX, Gurobi, and many more free and costly options. Today, we’ll be using Google’s OR-Tools.
Now you may ask, why MIP and not a regular LP? The Line Balancing Problem is a type of assignment problem, where binary variables are assigned. In our case, \(X_{ij}\) is 1 if station \(i\) is assigned process \(j\).
\[X_{ij} = \begin{cases} 1, & \text{if process $i$ is assigned to station $j$}\\ 0, & \text{otherwise} \end{cases}\]In our use case, the process is happening at that station, or not, and it cannot be anything in between. As we add constraints to the system, in a very simple case, this can produce an optimized result with a linear solver that isn’t actually workable in reality. For example, it may suggest we have 3.26 stations, when we can only have 3 or 4, but not in between. This may seem simpler, but is computationally more complicated, and requires us to use a MIP solver.
Problem Overview
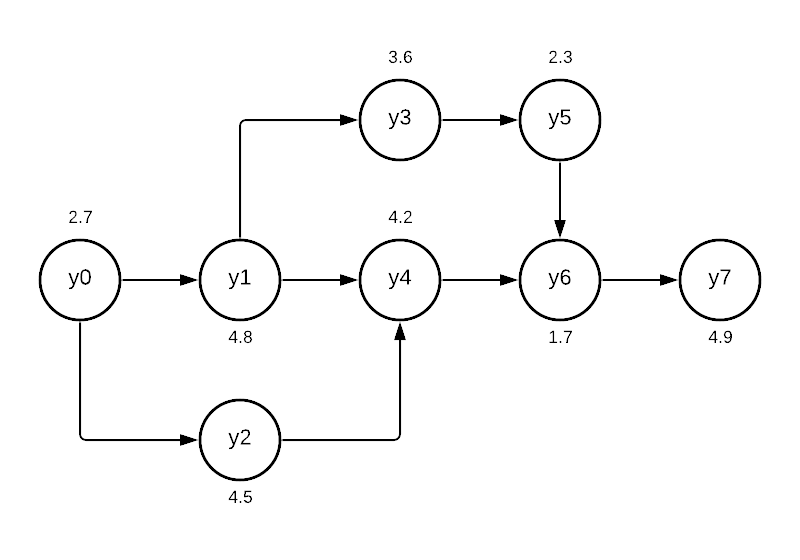
Let us imagine an eight-step process to build a widget that we are balancing. Besides this, our factory is available for eight hours a day, and we have a demand of 50 widgets per day. Times below are in minutes.
Note: You’re probably wondering why I labeled the process steps \(y_0, y_1, \dots, y_7\). This was to align with the zero-based array indexing in Python. This way, y[0] \(= y_0\) and not \(y_1\). You will notice this convention carries into the variable names in our mixed integer program. I found it easier to wrap my mind around when converting between array indexes and the actual variable I was looking for.
Before we enter the data into our program, let us pull in the packages and initialize our solver. We are going to use SCIP, but there are other options.
from ortools.linear_solver import pywraplp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
solver = pywraplp.Solver.CreateSolver('SCIP')
Based on the process flow, we can enter our data in an calculate our current line utilization.
no = 8 # number of process steps
steps = list(range(0, no))
process = ['Task %s' % s for s in steps]
ct = [ # cycle times
2.7, # y0
4.8, # y1
4.5, # y2
3.6, # y3
4.2, # y4
2.3, # y5
1.7, # y6
4.9, # y7
]
seq = np.array([ # predecessor , task
[0,1], # y0 is before y1....
[0,2],
[1,3],
[1,4],
[2,4],
[3,5],
[4,6],
[5,6],
[6,7],
])
avail = 8 * 60 # 8 hours converted to minutes
demand = 50
takt = avail / demand
util = sum(ct) / (takt * len(process))
rb = max(ct)
print ('Utilization:', util)
print ('Takt:', takt)
print ('r_b:', rb)
Utilization: 0.37369791666666674
Takt: 9.6
r_b: 4.9
Alright, not so great. With the system \(r_b = 4.9\) and the \(\text{Takt}=9.6\), we can see why the utilization is so low. To visualize this, we can put the data into a bar plot with the takt time.
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_ylabel('Cycle Time (Min)')
ax.bar(process,ct)
ax.axhline(y=takt)
plt.show()
We would like to have our cycle time at each station closer to the takt time to increase utilization. This will ensure that widgets exit the system at a rate equal to or faster than the demand, ensuring we keep our customers happy. A \(r_b > \text{Takt}\) doesn’t make enough parts in the day (too slow), and a \(r_b < \text{Takt}\) produces parts at a rate faster than we need them. Ideally \(r_b = \text{Takt}\), but we try to shoot for a little below to be safe.
\[\text{Takt} = \frac{\text{Available Time}}{\text{Demand}} = \frac{480}{50} = 9.6\]Defining Constraints
We have talked about minimizing a couple things now, specifically utilization through \(W\). To use a MIP solver, we need to translate our line balancing issue into and equation that can be minimized. To start, we need to initialize a decision variable for each task so we can assign a sequence.
infinity = solver.infinity()
y = {}
# create a integer variable yi for each process step
for i in range(len(process)):
y[i] = solver.IntVar(0, infinity, 'y%i' % i)
Following this, we need to create a binary variable for each \(X_{ij}\) where \(X_{ij}= 1\) if station \(i\) is assigned process \(j\). We have eight process steps that can be performed at eight stations, resulting in 64 variables.
\[X_{ij} = \begin{cases} 1, & \text{if process $i$ is assigned to station $j$}\\ 0, & \text{otherwise} \end{cases}\]a = 0
x= {}
for i in range(len(process)):
for j in range(len(process)):
x[a] = solver.IntVar(0, 1, 'x%i%i' % (i, j))
a += 1
Next up, we want to put in the sequence of tasks as a constraint. Since we are using integers, we can assign each unique process step a sequential value to ensure that we do not get things out of order. By using the sum of these values, we can create a simple way to ensure tasks do not get assigned to stations in the wrong order. For example, we can make sure Task 1 is before Task 2 with the constraint below. We will reference the sequence using our seq array.
for i in range(len(seq)): # sequence constraints
solver.Add(y[seq[i,0]] - y[seq[i,1]] <= 0)
If \(Y_0\) is assigned \(X_{0j}\) tasks where \(X_{0j} > X_{1j}\), it will cause \(Y_0 > Y_1\), breaking the constraint. We will add in another constraint that increments the value of \(Y_i\) based on the step it was assigned so this piece works.
\[\sum_{j} j\times X_{ij}= Y_i,\space \forall i\]for i in range(len(process)): # set Yi to enforce sequencing
constraint_expr = \
[(j+1) * x[((i*7)+j+(i*1))] for j in range(len(process))]
solver.Add(sum(constraint_expr) == y[i])
We want to make sure each station does not have more than the takt time worth of work at the station. The equation is the sum of each task \(j\) iterated across station \(i\) must be \(\leq \text{Takt}\). We also want to set the correct cycle time from our ct array as the coefficient for its respective \(X_{ij}\) variable.
for i in range(len(process)): # station CT does not exceed takt
constraint_expr = \
[ct[j] * x[i+(j*8)] for j in range(len(process))]
solver.Add(sum(constraint_expr) <= takt)
Another requirement is that we only performed each process at one station. We express this as
\[\sum_{i} X_{ij}= 1,\space \forall j\]for i in range(len(process)): # a given task is only at one station
constraint_expr = \
[x[((i*7)+j+(i*1))] for j in range(len(process))]
solver.Add(sum(constraint_expr) == 1)
Last, we want to pull the whole program together with our global variable to minimize \(Z\). In the same way we incremented the \(Y_i\) with process steps, we will create a constraint that increments \(Z\) every time a station is “activated” with a task. Since our aim is to minimize the number of stations, our objective function is quite simple:
\[\begin{aligned} & \underset{Z}{\text{minimize}} && Z \\ \end{aligned}\]To initialize this variable, we need to create a new integer with z = solver.IntVar(0, infinity, 'z').
In the previous step, we talked about creating a constraint that links the activation of \(Y_i\) to \(Z\). This is achieved rather simply.
\[Y_i \leq Z,\space \forall i\]for i in range(len(process)):
solver.Add(y[i] <= z)
The Mixed Integer Program
We have reached the end, and we can reflect so far on what we’ve accomplished. Outside of the specific sequence constraints (the \(Y_i - Y_{i+x} \leq 0\) stuff), the rest of the constraints should apply to almost any assembly line, and scale with size. Do not let the summation notation scare you, it’s mostly a bunch of monotonous addition. Below is our mixed integer program in all its glory.
\[\begin{aligned} & \underset{Z}{\text{minimize}} & & Z \\ & \text{subject to} & & Y_0 - Y_1 \leq 0 \\ & & & Y_0 - Y_2 \leq 0 \\ & & & Y_1 - Y_3 \leq 0 \\ & & & Y_1 - Y_4 \leq 0 \\ & & & Y_2 - Y_4 \leq 0 \\ & & & Y_3 - Y_5 \leq 0 \\ & & & Y_4 - Y_6 \leq 0 \\ & & & Y_5 - Y_6 \leq 0 \\ & & & Y_6 - Y_7 \leq 0 \\ & & &\sum_{j} j\times X_{ij} = Y_i,\space \forall i \\ & & &\sum_{j} \text{Cycle Time}_{j}X_{ij} \leq \text{Takt}, \forall i \\ & & &\sum_{i} X_{ij}= 1,\space \forall j \\ & & & Y_i \leq Z,\space \forall i \\ & & & X_{ij} \in \{0,1\} \\ & & & Y_i, Z \in \{0,\infty\} \\ \end{aligned}\]Using the Solver
We are ready to optimize. This is as simple as executing solver.Minimize(z), but requires a little more code to get anything meaninful.
status = solver.Solve()
if status == pywraplp.Solver.OPTIMAL:
print('Number of Stations =', solver.Objective().Value())
else:
print('The problem does not have an optimal solution.')
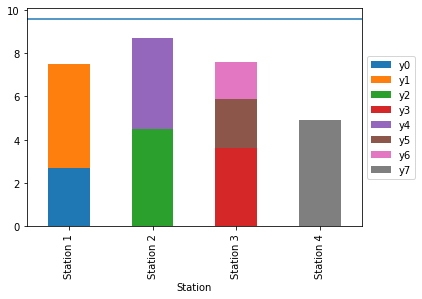
Number of Stations = 4.0
The results are out, and we know we can run this process with four stations, which is half of what we previously had. Now, let us visualize what the new process looks like.
station = []
task = []
names = ['Station %s' % s for s in station]
for j in range(len(process)):
station = np.append(station, ['Station %s'
% int(y[j].solution_value())], axis=0)
task = np.append(task, [y[j].name()], axis=0)
line = pd.DataFrame({'Task': task, 'CT': ct, 'Station': station})
ax = line.pivot('Station', 'Task', 'CT').plot(kind='bar', stacked=True)
ax.axhline(y=takt)
ax.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()
util = sum(ct) / (takt * solver.Objective().Value())
print ('Utilization:', util)
Outstanding, now we can see the new sequence of process steps and layout of the line. Our utilization is up to almost 75%, almost double from our baseline and right where we want the system running at.
I hope you found this tutorial educational, and I hope you can use the code to automate your next line balancing activity. Outside of inputting cycle time and sequence, be able to simply add or subtract process steps and the rest of the program should work automatically. Let me know if you have a success story!
Acknowledgements
The framework and approach for this post was adapted from Radsdale’s (2014) Spreadsheet modeling and decision analysis for Python with Google’s OR-Tools. Reference below.
Ragsdale, Cliff. Spreadsheet modeling and decision analysis: a practical introduction to business analytics. Cengage Learning, 2014.
Full Program
If you do not have a Python IDE, you can run this in the cloud! Check out my Colab Notebook. Remember you have to restart the runtime after executing the first cell. This simply means clicking the Play button again once it prompts to restart the runtime. Happy line balancing!
from ortools.linear_solver import pywraplp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
solver = pywraplp.Solver.CreateSolver('SCIP')
no = 8 # number of process steps
steps = list(range(0, no))
process = ['Task %s' % s for s in steps]
ct = [ # cycle times
2.7, # y0
4.8, # y1
4.5, # y2
3.6, # y3
4.2, # y4
2.3, # y5
1.7, # y6
4.9, # y7
]
seq = np.array([ # predecessor , task
[0,1], # y0 is before y1....
[0,2],
[1,3],
[1,4],
[2,4],
[3,5],
[4,6],
[5,6],
[6,7],
])
avail = 8 * 60 # 8 hours converted to minutes
demand = 50
takt = avail / demand
util = sum(ct) / (takt * len(process))
rb = max(ct)
print ('Utilization:', util)
print ('Takt:', takt)
print ('r_b:', rb)
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_ylabel('Cycle Time (Min)')
ax.bar(process,ct)
ax.axhline(y=takt)
plt.show()
infinity = solver.infinity()
y = {}
# create a integer variable yi for each process step
for i in range(len(process)):
y[i] = solver.IntVar(0, infinity, 'y%i' % i)
a = 0
x= {}
for i in range(len(process)):
for j in range(len(process)):
x[a] = solver.IntVar(0, 1, 'x%i%i' % (i, j))
a += 1
for i in range(len(seq)): # sequence constraints
solver.Add(y[seq[i,0]] - y[seq[i,1]] <= 0)
for i in range(len(process)): # set Yi to enforce sequencing
constraint_expr = [(j+1) * x[((i*7)+j+(i*1))] for j in range(len(process))]
solver.Add(sum(constraint_expr) == y[i])
for i in range(len(process)): # station CT does not exceed takt
constraint_expr = [ct[j] * x[i+(j*8)] for j in range(len(process))]
solver.Add(sum(constraint_expr) <= takt)
for i in range(len(process)): # a given task is only at one station
constraint_expr = [x[((i*7)+j+(i*1))] for j in range(len(process))]
solver.Add(sum(constraint_expr) == 1)
z = solver.IntVar(0, infinity, 'z')
for i in range(len(process)):
solver.Add(y[i] <= z)
solver.Minimize(z)
status = solver.Solve()
if status == pywraplp.Solver.OPTIMAL:
print('Number of Stations =', solver.Objective().Value())
else:
print('The problem does not have an optimal solution.')
station = []
task = []
names = ['Station %s' % s for s in station]
for j in range(len(process)):
station = np.append(station, ['Station %s'
% int(y[j].solution_value())], axis=0)
task = np.append(task, [y[j].name()], axis=0)
line = pd.DataFrame({'Task': task, 'CT': ct, 'Station': station})
ax = line.pivot('Station', 'Task', 'CT').plot(kind='bar', stacked=True)
ax.axhline(y=takt)
ax.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()
util = sum(ct) / (takt * solver.Objective().Value())
print ('Utilization:', util)